这是 JerryScript 官网的一段简介:
简单翻译一下:
JerryScript 是一个为 IoT 而开发的轻量级 JavaScript 引擎,可以运行在资源十分受限的设备上,比如:
- RAM 低于 64KB 的设备
- ROM 低于 200KB 的设备
该引擎支持在设备上解释、执行 JavaScript 以及对外围设备的访问。
说白了 JerryScript 和我们日常用的 Chrome 和 Node.js 中的 V8 是一回事,是一个引擎,只不过 JerryScript 能运行在更加低端的设备上,如嵌入式设备。我们知道,JavaScript 作为一个脚本语言有其先天的缺陷,如解释执行的效率低下以及臃肿的堆内存的占用,哪怕 V8 的设计与实现已经做了大量的优化与改进,但距离能运行在 RAM 以 KB 为单位的设备上还差得很远。这不禁使人产生疑问,同样是对统一标准的实现,JerryScript 凭什么做到运行在 RAM 低于 64KB,ROM 低于 200KB 的设备上这种骚操作。本文是对 JerryScript 的官方文档 的翻译。
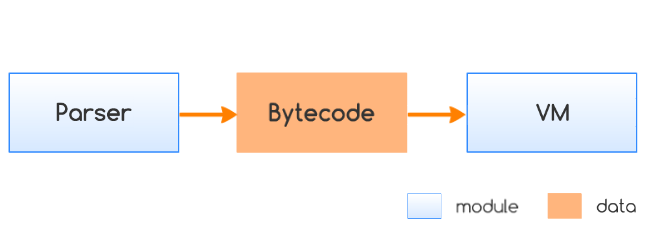
如上图,Parser(解析器) 和 VM(虚拟机) 是 JerryScript 的两个核心组件。一般来说 JerryScript 运行的基本流程,首先,Parser 将加载到的 JS 标准代码解析成具有特殊格式的字节码,然后由 VM 对字节码进行执行。
Parser
在 JerryScript 里,Parser 被设计为 recursive descent parser(递归下降解析器),这样的解析器可以直接将标准 JS 代码转换成字节码而并不像 V8 那样会构建一个 AST。这里的实现依赖以下四个组件:Lexer(词法分析器)、 Scanner、Expression Parser(表达式解析器)以及 Statement Parser(语句解析器)。
Lexer
将输入的代码字符串切分成标识符序列,其不仅可以按顺序向前扫描输入字符串,而且可以移动到任意位置。
Scanner
对输入的字符串进行预扫描并搜索特定字符,比如这一步可以确定出现 for 的地方代表了常规的循环还是 for-in 循环。
Expression Parser
负责解析 JavaScript 表达式。
Statement Parser
负责解析 JavaScript 语句。
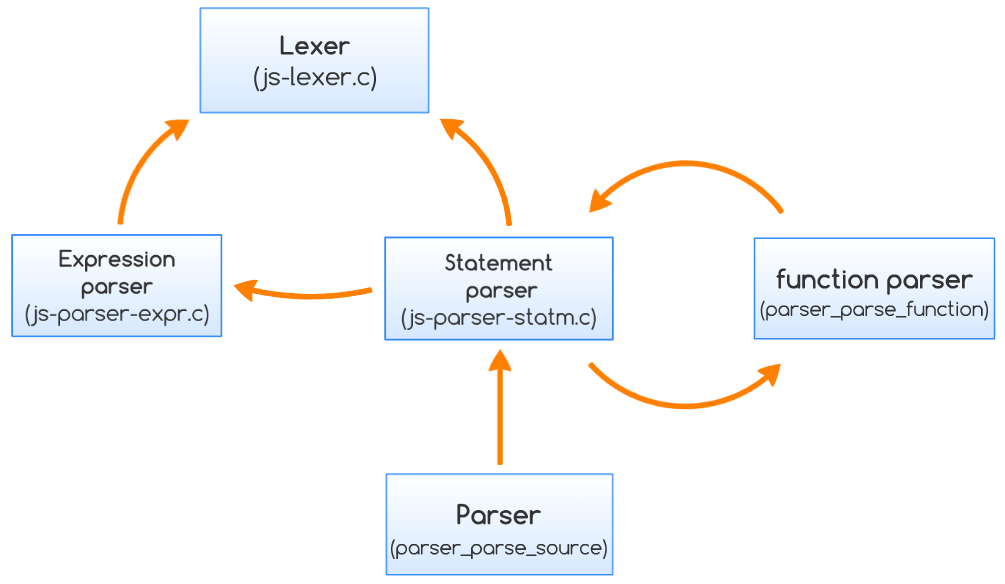
上图展示了 Parser 中几个主要组件的相互作用,函数 parser_parse_source 对输入的 ES 源代码进行解析和编译,当遇到函数时,调用 parser_parse_function对代码进行递归操作,包括参数解析和上下文处理。解析之后,parser_post_processing 函数转储创建的操作码并返回一个 ecma_compiled_code_t * 指针,它指向已编译的字节码序列。
Byte-code
与其他 JS 引擎的实现相比,JerryScript 实现了更加紧凑的字节码形式(CBC),和其他只关注性能的实现相比,一方面减少了字节码的内存消耗,同时又具有可观的性能。CBC 类似于 CISC 指令集,可为频繁的操作分配较短的指令。 许多指令表示多个原子操作,减少了字节码体积,这类似于一种数据压缩方法。
编译的字节码的内存布局

- header 表示一个具有多个域的 cbc_compiled_code 结构,这些域包含了字节码的关键属性。
- literial 部分是一个 ecma 值的数组,这些值包含了 ECMAScript 定义的数据类型,比如 string、number、function等等。该数组长度由 header 中的 literal_end 字段指定。
- CBC instruction list 是一系列的字节码指令,他们代表编译后的代码。
字节码内存布局

每一个字节码都由 opcode 开头。常见指令的 opcode 为1字节,反之稀有指令的为2字节。稀有指令的第一个字节始终为零(CBC_EXT_OPCODE),第二个字节表示扩展操作码。 常见指令和稀有指令的名称分别以 CBC_ 和CBC_EXT_ 前缀开头。
由于可以定义 255个公共指令(不包括零值)和256个稀有指令,因此 opcode 的最大个数是 511,目前大约有215条常见指令和70条稀有指令可用。
在 CBC 中有3种字节码参数:
- byte argument(字节参数):介于0~255之间的值,通常代表操作码操作调用的参数计数(函数、new、eval等)
- literal argument(字面量参数):在header中介于0~literal_end(包含0)之间的整数索引的域
- relative branch(相对分支参数):长度为1~3个字节的偏移量。分支参数也可能代表指令范围的结尾。 例如,
CBC_EXT_WITH_CREATE_CONTEXT的 branch 参数显示 with 语句的结尾。 更确切地说,with子句中最后一条指令之后的位置
参数之间的组合限于以下7种情况:
- 无参数
- 只有一个字面量参数
- 只有一个字节参数
- 只有一个分支参数
- 一个字节参数和一个字面量参数
- 两个字面量参数
- 三个字面量参数
Literal(字面量)
字面量被按照不同的类型组成字面量组,这与为每个字面量分配标志位相比更加节省空间。(以下提到的范围代表大于或等于范围左侧和小于右侧的那些标记。例如,字节码标头的ident_end和literal_end字段之间的范围包含这些标记, 大于或等于ident_end且小于literal_end。如果ident_end等于literal_end,则范围为空。)
identifiers(标识符) 和 values(值) 是两个主要的字面量组:
- identifier:表示变量的名字。在 header 中字面量值介于0~ident_end之间。这种字面量必须为 string 或 undefined。undefined只能用来表示该字面量无法通过字面量名字访问到的情况。比如
function () {arg, arg}有两个参数,但这里的 arg 只能用来引用第二个参数。在这种情况下,第一个参数的名字就是 undefined。此外,诸如 CSE 之类的优化也可能引入不带名称的字面量。 - value:表示立即值的引用。字面量值介于 ident_end 和 const_literal_end 之间的数字或字符串等。这种字面量可以直接被 VM 所使用。字面量值介于 const_literal_end 和 literal_end 的是模板字面量,比如函数和正则表达式。每次访问这类值都需要构造一个新对象。
identifiers 还有另外两个子组。寄存器是存储在函数调用堆栈中的那些标识符。 参数是由调用程序函数传递的那些寄存器。
在 CBC 中有两种类型的字面量编码,都是可变长度,1或2个字节。
- small:最多可以编码511个字面量
单字节编码 0 - 254 之间的字面量
1 | |
双字节编码 255 - 510 之间的字面量
1 | |
- full:最多可以编码 32767 个字面量
单字节编码 0 - 127 之间的字面量
1 | |
双字节编码 128 - 32767 之间的字面量
1 | |
因为大多数函数需要的字面量小于 255,所以 small 编码为所有字面量提供了一个单字节的字面量索引。与 full 编码相比,small 编码占用更少的空间但是范围有限。
Literal Store
JerryScript 没有用于字面量的全局字符串表,但是将它们存储在文字存储中。 在解析阶段,如果出现一个新的字面量,若其标识符与现有的标识符相同,则不会再次存储该字符串,但会使用字面量存储区中的标识符。 如果一个新的字面量不在Literal Store中,它将被插入。
Byte-code Categories(字节码类别)
字节码可以被分为四个主要的类别:
Push 字节码
Call 字节码
Arithmetic, Logical, Bitwise and Assignment 字节码(算数、逻辑、位、赋值)
Branch 字节码
Snapshot(快照)
编译后的字节码可以保存到快照中,也可以加载回执行。 直接执行快照可以节省解析源的内存消耗和性能成本。 也可以直接从 ROM 执行快照,在这种情况下,还可以节省将快照加载到内存中的开销。
Virtual Machine(虚拟机)
虚拟机是一个解释器,可逐一执行字节码指令。 解释的函数是位于 ./jerry-core/vm/vm.c 的 vm_run。 vm_loop是虚拟机的主循环,它具有非递归特性。 这意味着在函数调用的情况下,它不会递归地调用自身而是返回,这具有的好处是与递归实现相比不会加重堆栈。
ECMA
引擎中 ECMA 组件负责以下四个功能:
- 数据表示
- 运行时
- GC
数据表示
数据表示的主要结构是 ECMA_value,这个结构中低三位编码了数据标签,用来确定数据类型:
- simple
- number
- string
- object
- symbol
- error

如果是数字,字符串和对象类型,则该值包含一个编码的指针,对于基础值是一个预定义的常量,可以是:
- undefined
- null
- true
- false
- empty (未初始化的值)
压缩指针
为了节省堆空间,引入了压缩指针:

这些指针是 8 字节对齐的16位指针,可以寻址 512 Kb的内存,这也是 JerryScript堆的最大容量。 为了支持更多的内存,可以在构建时加上“ –cpointer_32_bit on”,将压缩指针的大小扩展到 32位,以覆盖 32位系统的整个地址空间。 “未压缩的指针”会将内存消耗增加大约20%。
数字
根据 IEEE 754标准有两种可能的数字表示形式:默认值是8字节(双精度),但是引擎也支持将 JERRY_NUMBER_TYPE_FLOAT64设置为0来支持4字节(单精度)表示方式。
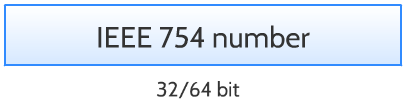
不支持多次引用单个分配的数字。每个引用都拥有自己的副本。
字符串
JerryScript中的字符串不仅是字符序列,而且还可以包含数字和所谓的 magic ID。 对于常见的字符序列(在 ./jerry-core/lit/lit-magic-strings.ini 中定义),只读存储器中有一个表,其中包含 magic ID和字符序列对。 如果一个字符串已经在此表中了,则将存储其字符串的 magic ID 而非字符序列本身。 使用数字可加快属性访问以达到节省内存的目的。
Object / Lexical Environment(词汇环境)
对象可以是常规数据对象或词法环境对象。 与其他数据类型不同,对象可以具有对其他数据类型的引用(称为属性)。 由于有循环引用,引用计数并不总是足以确定死对象。 因此,链列表是由所有现有对象组成的,可用于在垃圾回收期间查找未引用的对象。 每个对象的 gc-next 指针显示链表中的下一个分配对象。
Lexical environments 在 JerryScript 中实现为对象,因为其包含像对象一样的键值对(称为绑定)。 这简化了实现并减小了代码大小。

这些对象表现为如下结构:
引用计数器–硬(非属性)引用的数量
GC 的下一个对象指针
类型(函数对象或词汇环境等)
对象属性
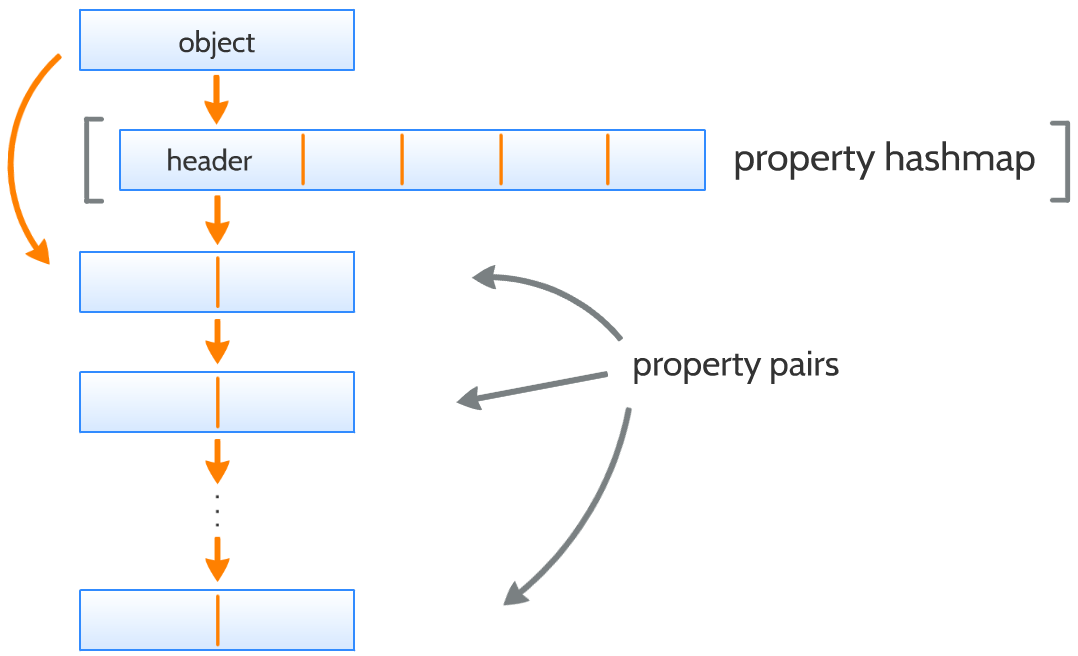
对象有一个包含其属性的链表。此链表实际上包含属性对,为了节省内存:属性占7位,其类型字段占2位,共9位,这样一个字节就不够用需要占用两个字节,因此,将两个属性(14位)与2位的类型字段放在一起这样就能沾满2字节。
property hashmap(属性hash表)
如果属性对的数量达到限制(当前此限制定义为16),则在属性对列表的第一个位置插入一个 Property Hashmap,以便使用它来查找属性,而不是通过在属性对上线性迭代来查询。
属性哈希表包含2^n个元素,其中 2^n 大于对象的属性数。 每个元素可以具有值的树类型:
- null,指代空元素
- delete,指代被删除的元素,或者
- 对现有对象的引用
hashmap 是必须返回的类型的缓存,这意味着可以通过它找到对象所有的属性。
内部属性
内部属性是一些特殊的属性,这些属性包含无法由 JavaScript 代码访问的元信息,但对引擎本身很重要。 内部属性的一些示例如下所示:
- [[Class]] – 对象的类(类型)(ECMA 定义)
- [[Code]] – 指向函数字节码的指针
- native code(原生代码)– 指向原生函数代码的指针
- Boolean [[PrimitiveValue]](基础值)– 存储 Boolean 对象的 bool 值
- Boolean [[PrimitiveValue]](基础值)– 存储 Number 对象的数值
LCache
LCache是用于查找由对象和属性名称指定的属性的哈希表。 LCache 的对象-名称-属性布局在一行中连续显示多次,如下图:
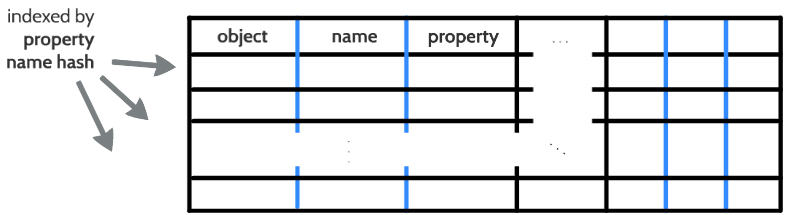
访问属性时,将从所需的属性名称中提取hash值,然后使用该哈希值对 LCache 进行索引。 然后在索引行中搜索指定的对象和属性名称。
值得注意的是,如果在 LCache 中找不到指定的属性,这并不意味着它不存在(即LCache是可能返回的缓存)。 如果找不到该属性,则将在对象的属性列表中对其进行搜索,如果找到该属性则会将该属性放入LCache中。
Collections
Collections 是类数组数据结构,优化用于节省内存。事实上,Collections是一个链表,其元素并非单个元素,而是一个包含多个元素的数组。
Exception Handling(异常处理)
为了实现异常处理,JerryScript 的返回值能指示其错误或异常操作。其返回值是一个 ECMA 值,若发生错误操作则返回 ECMA_VALUE_ERROR 值。
Value Management and Ownership(值管理和所有权)
引擎存储的每个 ECMA 值都与一个虚拟的 “所有权” 相关联,该所有权定义了如何管理该值:当不再需要它时何时释放它,以及如何将该值传递给其他功能。
最初,值是由其所有者(即用有所有权)分配的。 所有者有责任释放该值。 当将值作为参数传递给函数时,其所有权不会被传递,被调用函数必须制作一个自己的值副本。 但是,只要函数返回值,所有权就会传递,因此调用者将负责释放它。