这是2017年10月到2018年10月在全民直播期间的一个项目,因为在直播公司的缘故,所以会涉及很多直播相关的业务。当时有几家做的比较好的直播平台,比如斗鱼、虎牙、熊猫、战旗、全民等,直播内容都以游戏、才艺表演为主,直播受众广,每天产生的数据流量巨大,公司为此启动一个新项目,采集全平台直播数据,并经大数据技术清洗统计后为直播行业提供数据化运营解决方案。
加入全民直播的时候正值刚毕业不久,从河北来到杭州,机缘巧合就入职了全民,接手了这一项目,因为当时负责项目开发的工程师即将离职,因此我也算紧急受命。对那时候的我来说,这个项目算是相对难度最高的,为什么这样说呢?首先因为我本身并不是计算机科班出身,再加上在学校自学的经历,虽也接触过不少的技术,但都不深入,所以当初次接触到这种成体系的项目时就显得有些局促了。当然,项目本身也算是难度比较大的,由于是后期接手的缘故,所以也就没有参与初期技术方案的设计,但其中的细节还是值得考虑的。本文即是复盘当时项目的业务及技术细节,结合接手项目后及二期改进所做的工作,对当时碰到的问题及技术方案设计进行整理和思考。
简单介绍一下业务
如果你看过游戏直播(如果没看过现在可以打开看看,比如斗鱼、虎牙)就会比较熟悉,当打开一些热门网红的直播主页时会看到很多内容,首先是源源不断刷过整个屏幕的弹幕,还有一些粉丝送给主播的礼物(比如火箭),这些都算是动态数据,而且从全网来看数据量巨大。其次还有很多相对静态的内容,比如主播名称、热度、关注度等相关信息。对于做直播业务的公司来说,这当然是有价值的。因此我们要做的事情就是把这些动态和静态的数据源源不断地从网络上抓取下来,并通过一些大数据手段进行清洗和计算,最后得到一个全网主播的动态信息汇总平台,并向行业内相关人士或机构提供大数据咨询服务。
面临的问题
从技术层面思考这个事情,其实简单来说我们要做的就是通过一些手段把上面说的各种静态和动态数据从各个直播平台上抓取下来(说白了就是爬虫),然后通过一个大数据清洗和计算流程汇总得到业务所需的形态,最后通过网页或 app 的形式把数据展示给用户。
业务目标清楚了,接下来从技术角度梳理一下做这个事情可能会碰到什么问题:
- 直播平台众多,各平台无兼容性:当时正值娱乐直播业务的红海期,各种直播平台相互竞争,首期决定采集的平台有斗鱼、虎牙、龙珠、战旗、触手、熊猫、全民。
- 涉及数据类别有多种,协议层适配和数据清洗会很复杂:首期决定采集的直播数据有弹幕、礼物、主播个人信息、主播热度及关注度
- 可能会遭到平台方的封锁:毕竟是爬虫,你懂的(不过不像现在,当时还没有这么严重的法律风险)。
- 从直观上看数据量可能会很大:最终从事实上来看确实很大,数据的采集、计算、存储、读取都需要考虑这方面因素。
技术选型及解决方案
语言:Node.js / Go(二期升级时采用)
数据库、缓存及静态存储:MySQL、Redis、阿里云 OSS
数据搜索服务:Elasticsearch
服务器:阿里云 ECS
流数据池子:阿里云日志服务
前后端:Express / Koa / Vue
冷数据存储:阿里云 ODPS
服务器监控:Grafana / Alinode
部署方案:GitLab CI / Ansible
大数据清洗和计算:阿里云实时计算
平台及数据兼容层
前面提到,首期业务决定采集斗鱼虎牙等7个平台的数据,深入看一下这几个平台的数据采集方式(由于当时有专门的团队已经做过相关工作,因此假设此时已经得到各个平台可用的 api 及接口访问权限,全民属于自有平台,接口信息也可看作已知)会发现每个平台都是不一样的,从接口协议层面看,因数据类别不同涉及到的协议有 TCP、WebSocket 以及 Http,动态数据如弹幕和礼物因为实时性比较强所以一般都是用 TCP 和 WebSocket 传输,当然也有比较奇葩的用 Http 的(比如触手)。静态数据如主播个人信息、关注度等则基本都是 Http 接口,当然也有不提供特定接口而直接从后端渲染的,不过本质上没有太大区别,只是后期处理上会稍显繁琐。
为了解决上述问题,比较通用的做法是在所有平台之上建立兼容层,将需要采集的数据分为 弹幕/礼物、主播信息、热度、关注数四大类,并抽象出其中的接口及事件。
如对于弹幕/礼物数据的采集模块来说会抽象出如下接口和事件:
init:按平台需求进行鉴权、Socket 连接及开启数据监听(针对 TCP 和 WebSocket)、初始化轮询请求(针对Http)以及请求一些附加的平台数据操作。
destroy:断开连接停止采集。
connect 事件:监听连接事件。
data 事件:接收请求到的数据,并进行相应的后续处理。
error 事件:等待超时或出现错误,则停止采集或进行重连。
close 事件:正常关闭操作。
在兼容层的上层,则按照采集到的数据的不同格式及类型建立 ETL 层对数据进行清洗得到平台通用的数据格式,架构示意图如下:
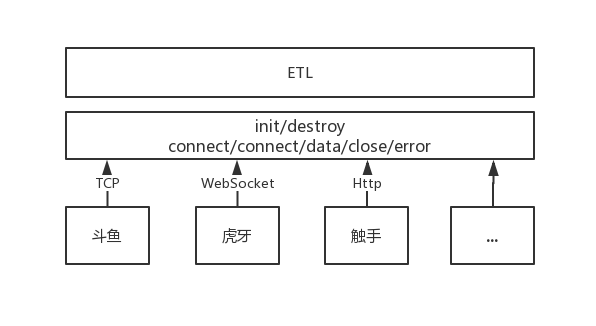
对于主播信息、热度、关注数类别的数据处理方式也是类似,针对平台差异抽象出不同平台的接口共性,并在使用时按平台调用。
采集集群
如果打开一些热门网红的直播间会发现在其直播期间,屏幕上会飘过海量的弹幕和礼物,从全平台来看,这些数据的量是非常大的,在项目维护期间我也曾做过粗略的统计,发现每天流过系统的数据量达到 400 - 600G,也就是说每天采集到的数据能装满一个 500G 的硬盘,这还只是清洗过后的,且不计图片、头像等数据,如果按照清洗前的量将大大超出这个值。要实现将这个量级的数据实时地从网络上抓取下来并集中清洗,势必需要多台服务器配合组成集群,将负载分配到每一个节点,并能根据采集量动态伸缩集群容量,达到业务和成本的平衡。
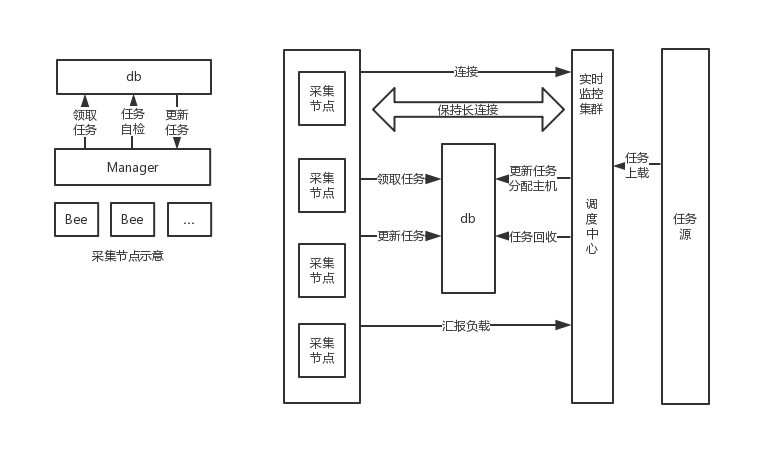
集群架构设计如下图:
任务系统
要采用集群化采集方案,则必然设计一套任务系统,将采集任务细化、标准化。这里还会涉及到另一个数据需求,即直播间开关播状态。因为当时并没有获取直播间状态的方法,因此采用列表对比的方式获得相对准确的直播间开关播状态,原理简单来说就是定时拉取平台的直播间列表并存储到 DB 中,等下一次再拿到列表时与 DB 中的列表对比得出开关播状态。如 DB 中已有 A、B、C 三个直播间状态为开播,下一次拿到的列表为 A、B ,则此时判定 C 直播间关播,以此类推。开关播状态除了本身是数据需求的一部分以外,还是采集节点采集数据与否的依据,因为观察发现,当主播关播时,直播间将没有或只有少量弹幕礼物数据刷过,这一部分数据可以忽略不计,为此当主播关播时关闭采集可以节省成本。
使用一台单独的服务器拉取各个平台主播列表作为任务源,拉取时间间隔为 1 分钟,主播列表中会包含主播详细信息并将该信息存到一张单独的表中。拉取到的列表按不同平台分批发送至调度中心,由调度中心来完成直播间状态的比对,并将该信息更新到 DB 中。
调度中心
调度中心会负责两方面的任务,一个是上面提到的,接受来自任务源的任务队列,并与 DB 中已有的任务进行比对得出需要更新的直播间状态。另一个则是分配任务。
采集集群会在启动时与调度中心取得长连接,采集节点会告知本机的局域网 IP 地址(集群中所有节点都在同一个局域网内),并将本机采集负载(采集任务数)通过 RPC 接口的方式暴露给调度中心,保持长连接意味着采集节点的状态变化可以实时地被调度中心感知到,调度中心依据此维护一个可用的采集节点列表(即 IP 列表),并能通过 RPC 机制实时地获取每个节点的负载。当调度中心收到来自任务源的任务列表时会比对得出所有需要更新采集状态(开启或停止采集)的任务,如遇到需要新开采集的任务时,会在可用的采集节点列表中选取一个负载最小的节点,将该节点 IP 与该任务绑定,赋予任务状态为 ACCEPT,表示该任务为新接收的任务,并将该任务存至任务列表。同时,若调度中心感知到某节点出现异常,比如断开连接,则调度中心会将任务列表中标记给该节点 IP 的所有任务取出,重复上述步骤,选取一个负载最小的节点,将该任务分配给该节点,若出现问题的是某任务,则调度中心会为其重新分配一个节点,该任务会被该节点发现并重新开启采集。这样一来,所有任务将在整个采集集群中动态平均分配,并在节点异常时及时回收任务再分配,以此平衡所有节点的负载,并将节点异常带来的数据损失降到最低。
集群
采集集群的工作即按平台差异以不同的方式从各个直播平台源源不断地拉取数据,集群中每一个节点都是等价的,集群规模也可以动态伸缩。集群节点服务主要以两部分组成:Manager(任务管理器)和 Bee(采集器)。Manager 是集群节点的主体,一方面在节点启动时,Manager 会与调度中心连接并实时同步 IP 信息和负载水平,另一方面,因调度中心已实时地将各个需要开启和关闭的任务同步至任务列表中,Manager 会定时到任务列表中领取与本机 IP 相匹配的任务进行相关操作,如开启或关闭采集。采集的主体即 Bee(命名取自小蜜蜂采集花蜜),当 Manager 拿到一个需要开启采集的任务时,会初始化一个 Bee 实例,Bee 初始化时会按照指定平台调用实现了特定接口的客户端与平台方取得连接,并将列表中任务状态改为 RUNNING,Bee 会接受来自平台的数据流,并调用特定的方法对数据流进行解析、计算、清洗,最终以统一的格式写入阿里云日志服务。也就是说,一个采集结点中只有一个 Manager,但该 Manager 会管理多个 Bee 实例。当某个 Bee 实例出现异常,比如与平台断开连接,则 Bee 会停止采集并将该任务标记为 FAILED,后续该任务会被调度中心发现并重新分配。同理,当 Manager 拿到一个待关闭任务时,则将该任务标记为 CLOES,后续该任务会进入关闭流程,关闭与平台的连接,并从任务列表中清除。
初期集群规模为 40 台阿里云 ECS 服务器,并通过 Ansible 统一部署与管理。每个集群上的任务数和资源占用水平都可以通过 Grafana 查看。从最终结果看来,全平台高峰期同时开播的直播间最高为 10 万个,也就是峰值任务约为 2500 个/台,LogHub 流数据为 400 - 600 G/天,这都在系统各个部件的承受范围内。且所有服务器都通过 Alinode 进行实时监控。
规避风控
前面已经提到过,该采集任务可能会碰到平台封锁的问题,事实上也是如此,且在业务后期平台封锁问题已成为整个服务的最大瓶颈。平台的封锁主要集中在任务源处,若直播平台封锁任务列表的拉取,会导致采集任务无法更新,最终导致数据与实际数据差距巨大,造成业务上数据不可信。因此解决该问题一直是最重要的任务。当时采取了以下几种方式:
- 规避平台风控规则:平台的封锁规则一般都和拉取频率有关,若拉取频率超过平台规定的阈值,会导致封锁。因此在拉取列表时尽量规避,该方法成本低,虽造成任务更新不及时,但也算保全了一部分数据,总体来看效果一般。
- 通过 CDN 节点拉取数据:直播平台一般都会有大量 CDN 节点,因此可以借助 CDN 进行数据拉取。但实施后发现 CDN 节点部署位置较分散,甚至有很多部署在国外,虽说这样做规避了一部分封锁的风险,但由于拉取速度太慢,总体效果不好,最终放弃该方案。
- 代理:终极解决方案,通过专门的爬虫代理服务器对目标平台进行请求,最终实现了较平稳的数据流输出。唯一的缺点是该方案成本较高。
计算
本系统中采集到的所有数据,除了主播信息、主播关注度、图片等少量且静态的数据存储在 MySQL 和 OSS 以外,其他动态数据都被存至阿里云 LogHub 日志服务中,主要原因是 LogHub 成本极低,且能在阿里云平台上动态查询检索数据,又由于 LogHub 与阿里云实时计算已实现了无缝对接,所以将其作为消息队列使用,业务过程中曾经考虑使用 Kafka 作为消息队列,但由于部署成本较高,且若使用 Kafka,则后续实时计算和流计算都需考虑自行部署(当时是这样),因此一直坚持使用 LogHub。
由于大数据计算部分是由另外一名同学专门负责的,因此我当时也没有参与相关操作,这里不再赘述。由于经过计算后的数据量仍然极大,以此该同学已考虑到将所有结果数据按照时间(大部分数据区分到月份,部分数据区分到日期)分表存放,以便于后续服务读取。
服务
业务的最终目标是将上述采集、清洗计算得出的数据以数据平台的方式展示给用户,因此最终的产品形态是一个网页,主要由 Koa + Vue 实现,其中涉及到数据的读取,由于数据量较大,因此前期会将一部分数据按照热度进行缓存以提高读取效率。因该服务也是另一位同学专门负责,其中涉及的技术主要有 Web 服务、用户系统、数据库 CRUD、API 接口等,与一般 Web 服务没有太大差异,因此在此不再赘述。
还没完
由于业务上的需求以及技术迭代,该项目进行了二期改造。其中会涉及到更多的技术细节,如调度中心的单点问题、任务分配机制有没有更好的方案、如何提高本地数据清洗效率等等。本文即较完整地阐述了直播大数据采集一期项目的技术实现细节,原本打算将二期也一起讲述,但由于涉及细节太多,目前篇幅已过长,因此决定将二期内容放到下一篇文章详细讲述。
本人一直坚持,技术没有好坏。而技术也一定是与业务的平衡和取舍。如有不明确或错误的地方欢迎留言或指出~不喜勿喷 :)