Pipcook,一个旨在降低机器学习在前端开发领域使用成本的开源项目。
什么是机器学习??
来看看维基百科的解释:

大概意思是,机器学习是一种通过算法建立一个数学模型,利用 “训练数据” 在没有明确编程的情况下做出预测或决策的机制。接下来借用 Tensorflow 中文社区的一个比较通俗易懂但又不至于太 “失真” 的例子来讲一下我理解的机器学习。
通过计算机视觉来识别手写数字是一个很好而且非常常用的演示机器学习的例子,比如看一下这张图片:
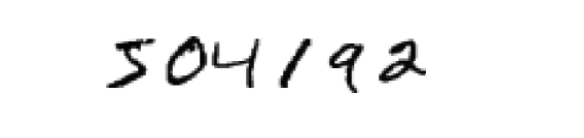
对于肉眼的我们来说这太简单了,我们可以轻易读出这是手写的数字 “504192”,这是由于人类通过亿万年的进化以及我们自身若干年的学习,使得我们的大脑对这种图片形式的信息异常敏感,以至于这个过程在不知不觉间就发生了。但假如我们用计算机来实现这个过程就会发现没那么简单。
我们可以回味一下我们自己识别这串数字的过程。首先我们看到几个黑色的痕迹,比如第二个圆圆的,以及第五个,上半部分圆圆的,下面拖着一个尾巴,幼儿时期的启蒙教育告诉我们,圆圆的那个是数字 “0”,而上半部分圆圆的而且还拖着一条尾巴的那个是数字 “9”。
那么将这个过程映射到机器学习的机制上是否也可行呢?事实上机器学习算法可能(为什么说是可能?后面会说)也是利用了这个思路,比如,将黑色痕迹的像素信息输入计算机,计算机会读出整体图片的某些部分是深色而且连续的,将这些部分连起来就是一个圆,这个时候计算机可能会判定这个图片上画的可能是一个数字 “0”,就像这样:
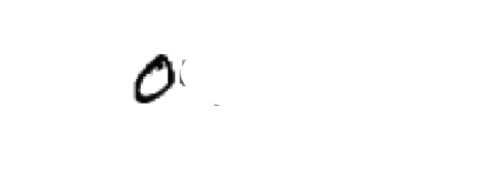
但是假如识别图片的机制就是像这样简单通过像素来判定的,那未免也太普通了,当然这也就不能叫机器学习了,简直就是赤果果的编程。其实,机器学习的精髓就在于通过大量的训练数据和验证数据让计算机自己去发现这套识别的机制(这也就是为什么我前面说的是“可能”,因为这只是我想的,可能计算机跟我“想”得不一样呢~)
简单表示一下这个过程:
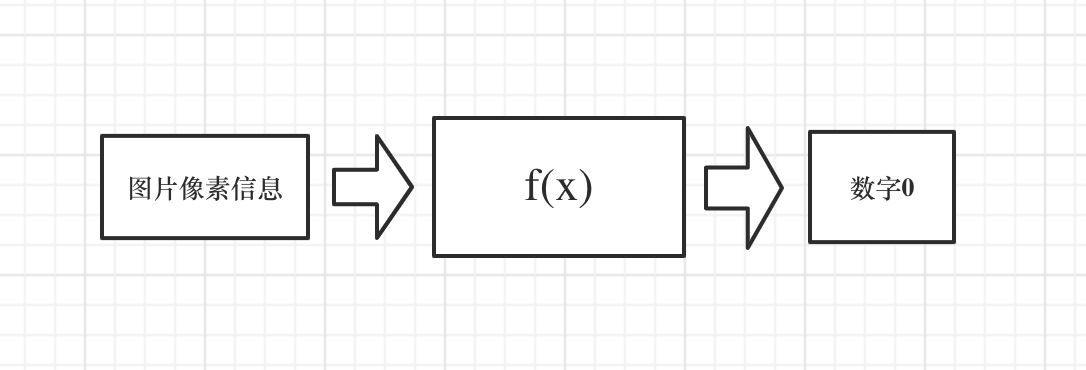
现在我有一个黑盒子 f(x),这个黑盒子的作用是在一端输入一个图片的像素信息,然后在另一端得到一个预测的数字,比如 “0”。最开始的时候,这个黑盒子并不是很好使,可能会出现错误的值。接下来我们去找大量类似的手写数字作为训练样本来训练和验证这个黑盒子,就像这样:
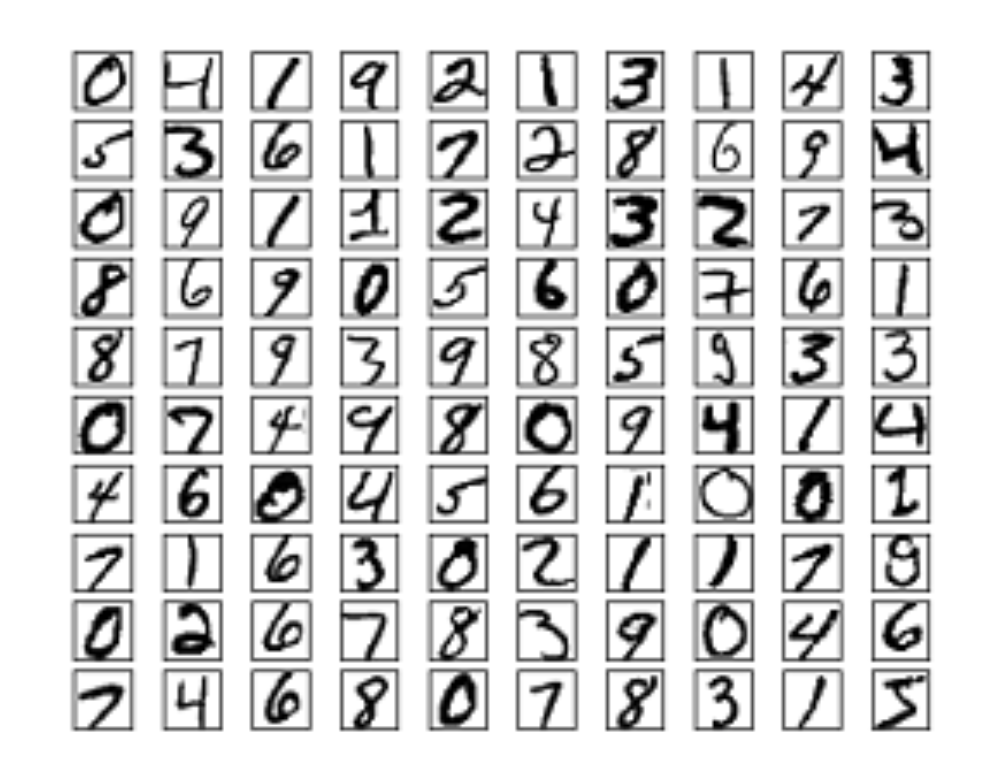
事实上,要训练出一个具有实际意义的机器学习模型仅有这么点样本是远远不够的。接下来把整个数据集分成两部分,一部分用来流过这个黑盒子来得到更加精确的黑盒子,训练的时候将图片信息输入 f(x),但这个时候也会告诉 f(x) 此时应该得到数字 “0”,并在 f(x) 确实输出 “0” 的时候给予一定的激励,此时在算法的作用下,f(x) 就会发现如此判断一个手写数字貌似是可行的,于是加重这种模式的比重。最后使用剩下的数据来验证一下这个模型 f(x) 的精确度。
当然,实际上机器学习算法的复杂度要远远高于上述所说,推荐阅读 Tensorflow 中文社区的几篇文章:
http://www.tensorfly.cn/special/deeplearning/chap1.html
这几篇文章描述了机器学习的大概思路与实现机制,还算是通俗易懂,只要你在大学学过高数读起来应该就没什么障碍。
机器学习,看上去还是高大上的,那作为开发者,我们可以用机器学习来做什么呢?
Pipcook 就是这样一个项目,它将机器学习的数据集、训练、模型评估等过程都进行了封装,换句话说 Pipcook 就是将机器学习的细节做成了一个黑盒子,让开发者可以在不了解机器学习机制的情况下使用机器学习助长生产力。
那 Pipcook 又是怎样运作的呢?
还是用上面的识别手写数字来作为例子吧!假设我是一个前端工程师,被996压榨的我现在有个需求,网页上有个按钮,点击上传一张写着数字的图片,然后得到一个这个数字的预测值,比如 “0”。老板要求直接使用机器学习来做,这样才能彰显公司强大的研发能力。
这在没有 Pipcook 的时候简直是不可想象的,我可能要去找大量数据集,然后阅读机器学习论文,自己训练模型并评估……(要是能干这个我简直就成天才了)。而现在,Pipcook 已经搞定了一切。
在使用 Pipcook 之前需要先安装一下,这个过程比较简单,可以读一下文档:
https://github.com/alibaba/pipcook
首先,一个机器学习的流程可能会分为几个阶段:
- 收集样本数据集并进行处理,然后分成训练集和测试集
- 选择用于训练的模型
- 将训练集用于模型的训练
- 用测试集评估训练出来的模型
这里,Pipcook 将这些过程很贴心地做了封装和集成,并用一个 json 文件来表示,就像这样:
1 | |
Pipcook 用几种不同的插件类型来表示机器学习中不同的阶段,并可以在阶段执行过程中对数据进行拦截和处理。
Pipcook 运行起来也是相当简便:
1 | |
训练结束后会生成一个 output 目录:
1 | |
优秀!竟然直接生成了一个 npm 包,简直就是加班狗的福音。可以在 js 项目中直接调用这个包,就像这样:
1 | |
启动服务并请求:
1 | |
通过上述简单地操作就完成了一个机器学习项目的创建和运行,而我要做的就是收集数据集,并编写一个用于 Pipcook 的 json 文件,然后运行得到 npm 代码包,是不是很简单?作为加班狗的我终于可以交差了。
当然,上述所说只是 Pipcook 最普通的一种用法,对于 Pipcook 来说我们想做的远不止于此,我们期望在此基础上拿出更加通用、简便的机器学习工程化解决方案,使得机器学习真正成为程序员的得力工具:)
更多内容请了解 Pipcook